探索
この章では新しいJavaScript固有の概念を紹介しない。代わりに、2つの問題への解を見ていこう、面白いアルゴリズムとテクニックを論じる。もし、面白そうだと思えなかったら、飛ばして次の章に進んでもらっても構わない。
最初の問題を紹介しよう。この地図を見て欲しい。太平洋の熱帯の小さな島、ヒバオアだ。
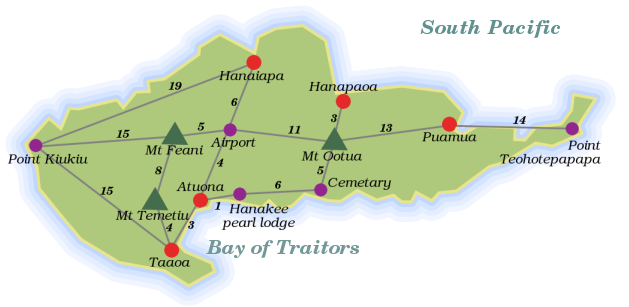
灰色の線は道路、傍らの数値はこれらの道路の長さだ。ヒバオアの2つの地点の間の最も短いルートを見つけるプログラムが必要であると想像しよう。どのようにアプローチすれば良いだろうか?これについてしばらく考えてみよう。
いや本当に考えるのだ。次の段落に強引に進んではいけない。可能な手段について真面目に考え、問題に対してどう取り組むか考えるのだ。技術的な本を読むとき、テキストを俯瞰するのは簡単で、厳粛にうなづき、読んだことは忘れてしまう。もし問題を解くために誠実に努力すれば、それはあなたの問題となり、その解もより意味のあるものとなるだろう。
この問題の最初の面は、繰り返すと、データをどう表現するかだ。図の情報はコンピューターにとってはあまり意味をなさない。この地図を見てその中の情報を展開するプログラムを書いてみよう…しかしそれは複雑になりかねない。もし20,000もの地図を翻訳しなければならないとしたらこれはいいアイデアになりうる、今回は我々自身で翻訳し、コンピューターにとって扱いやすい形式に書き起こそう。
我々のプログラムは何を知る必要があるだろうか?それは接続されている場所を見つけられること、そしてそれらの間の道路の長さである。島の場所と道路を数学者がグラフと呼ぶの形にする。グラフを格納する方法はたくさんある。単純で可能性としては、2つの終端と長さをプロパティとして持つ道路オブジェクトの配列として格納するのだ…
var roads = [{point1: "Point Kiukiu", point2: "Hanaiapa", length: 19},
{point1: "Point Kiukiu", point2: "Mt Feani", length: 15}
/* and so on */];
しかしながら、プログラムはルート、交差点に立っている人が、”Hanaiapa: 19km, Mount Feani: 15km”という標識を見るように、ある決まった場所からスタートする全ての道路のリストをとても頻繁に手に入れる必要があることが判明している。
これを表現するのに、道路の全体のリストをふるいにかけ、毎回この標識のリストに関係ある場所をつまみ出す必要がある。よりよいアプローチはこのリストを直接格納することだろう。例えば、場所の名前に結びついている標識のリストを持つオブジェクトを使う。:
var roads = {"Point Kiukiu": [{to: "Hanaiapa", distance: 19},
{to: "Mt Feani", distance: 15},
{to: "Taaoa", distance: 15}],
"Taaoa": [/* et cetera */]};
このオブジェクトを持っているとき、Point Kiu Kiuから移動する道路を得ることは、ちょうどroads["Point KiuKiu"]を探すことになる。
しかしながら、この新しい表現は重複した情報を持っている:AとBの間の道路はAとBの両方にリストされることになる。最初の表現は既にタイプするのに多くの労力をかけているので、これでは余計悪い。
幸運にも、命令を出してコンピューターの才能をこの反復的な仕事に充てることができる。個々の道路について、一度、コンピューターに正しいデータ構造を生成させるのだ。まず、roadという空のオブジェクトを初期化して、makeRoad関数を書こう。:
var roads = {};
function makeRoad(from, to, length) {
function addRoad(from, to) {
if (!(from in roads))
roads[from] = [];
roads[from].push({to: to, distance: length});
}
addRoad(from, to);
addRoad(to, from);
}
よさそうじゃないか?内側の関数addRoadはそのパラメータとして外側の関数を同じ名前(from、to)を使っていることに注意。これは邪魔にならない:addRoadの内側ではaddRoadのパラメータが参照され、その外側ではmakeRoadのパラメータが参照される。
addRoadの中のif文は、目的地の配列にfromの場所が既に存在するか確認して、もし既に存在しているのでなければ空の配列を入れる。これで、次の行では配列があり、それに新しい道路を入れてもいいと仮定できる。
今、地図の情報はこのようになっている。:
makeRoad("Point Kiukiu", "Hanaiapa", 19);
makeRoad("Point Kiukiu", "Mt Feani", 15);
makeRoad("Point Kiukiu", "Taaoa", 15);
// ...
[演習 7.1]
上記の記述において、"Point KiuKiu"という文字列は3つの行を持っている。複数の道路を1行で指示できるように記述をもっと簡潔にできる。
奇数の数の引数を取り、1つめは道路の常に開始地点、終了地点と距離を、その後の引数のペア毎に取るmakeRoads関数を書け。
makeRoadの機能と重複させず、しかしmakeRoadsがmakeRoadを呼び出して実際の道路を作らせるように。
[解答を見る]
function makeRoads(start) {
for (var i = 1; i < arguments.length; i += 2)
makeRoad(start, arguments[i], arguments[i + 1]);
}
この関数はstartという1つの名前付きパラメーターを使い、argumentsの他のパラメーターは(疑似的な)配列である。iが1から始まるのはこの最初のパラメーターをスキップするためだ。あなたも思い出したように、i += 2はi = i + 2を短縮したものだ。
var roads = {};
makeRoads("Point Kiukiu", "Hanaiapa", 19,
"Mt Feani", 15, "Taaoa", 15);
makeRoads("Airport", "Hanaiapa", 6, "Mt Feani", 5,
"Atuona", 4, "Mt Ootua", 11);
makeRoads("Mt Temetiu", "Mt Feani", 8, "Taaoa", 4);
makeRoads("Atuona", "Taaoa", 3, "Hanakee pearl lodge", 1);
makeRoads("Cemetery", "Hanakee pearl lodge", 6, "Mt Ootua", 5);
makeRoads("Hanapaoa", "Mt Ootua", 3);
makeRoads("Puamua", "Mt Ootua", 13, "Point Teohotepapapa", 14);
show(roads["Airport"]);
便利な操作を定義することで、道路情報の記述を考えられるだけ首尾良く短くできた。我々のボキャブラリーを展開してもっと短く情報を表現できるというかもしれない。このような’小さい言語’を定義することはしばしばとてもパワフルなテクニックであるが、場合によっては、繰り返しに、または冗長なコードを書くことになりかねないから、これを短く緊密にするためにボキャブラリーを思いつかないか試すのはやめておこう。
冗長なコードは書くのに退屈するだけではない、エラーの原因にもなり、人々は考える必要のないことに捕われて注意力を奪われる。その上、繰り返しのコードは変更しにくい。なぜなら、その構造が100度も繰り返されたら、誤っているか次善のものと判明したときに変更も100度繰り返さなければならないからだ。
もし上のコードの全ての部品が動いたら、そのときには島の全ての道路を含んでいるroadsという変数がある。決まった場所から開始する道路が必要になったとき、roads[place]とすることができる。しかし、それから誰かが場所の名前を誤ったとき、好ましくないことにこれらの名前は存在せず、期待した配列の代わりにundefinedを得ることになり、おかしなエラーが続いて起こる。代わりに、道路の配列を取り出し、未知の場所を与えられたときには叫ぶような関数を使うようにしよう。:
function roadsFrom(place) {
var found = roads[place];
if (found == undefined)
throw new Error("No place named '" + place + "' found.");
else
return found;
}
show(roadsFrom("Puamua"));
これは経路検索アルゴリズムの最初のスタブで、ギャンブラーのメソッドを使っている。:
function gamblerPath(from, to) {
function randomInteger(below) {
return Math.floor(Math.random() * below);
}
function randomDirection(from) {
var options = roadsFrom(from);
return options[randomInteger(options.length)].to;
}
var path = [];
while (true) {
path.push(from);
if (from == to)
break;
from = randomDirection(from);
}
return path;
}
show(gamblerPath("Hanaiapa", "Mt Feani"));
道路の全ての分岐で、ギャンブラーはサイコロを振って進む道を決める。もしサイコロが彼の来た道を選んでも、そうする。島の道路は全て繋がっているから、速かれ遅かれ、彼は目的地にたどり着く。
もっとも混乱するのはおそらくMath.randomを含む行だろう。この関数は0から1までの疑似乱数 [^1]の数値を返す。試しにコンソールから2, 3度呼び出してみれば、(ほとんど場合は)毎回異なる値を返すだろう。randomInteger関数はこの数値に与えられた引数の値をかけて、Math.floorで切り捨てた値を返す。それゆえ、例えば、randomInteger(3)は0、1、2のいずれかの数値を作る。
[^1] コンピュータは決定論的な機械である:常に受けた入力に同じように反応し、真の意味でランダムな値を作り出すことはできない。だから、ランダムであるかのように見える一連の数値を作らせて、それを行うのだが、実際にはそれはある複雑な決定論的な計算の結果である。
ギャンブラーメソッドは構造と計画を嫌う者、冒険を探すのに夢中な者の手段だ。我々に必要なのは、そのようなものではないから、場所の間の最も短いルートを見つけ出せるプログラムを書くことに着手しよう。
このような問題を解決するとてもまっすぐなアプローチは’生成とテスト’と呼ばれる。このようになる。:
- 可能な全てのルートを生成する。
- この集合について、実際に開始地点から終了地点に至る全ての接続から最も短いものを探す。
ステップ2は難しくない。ステップ1は少々問題だ。もしこれらが周回するのを許せば、無限の長さのルートになるだろう。もちろん、周回するルートはどこに行くにしても最短のものにはなりえないので、スタート地点からスタートしないルートはそれ以上考慮する必要がない。ヒバオアのような小さいグラフについては、決まった場所からの全ての周回しない(サイクルフリー)ルートを生成することは可能だろう。
しかし1つめについては、新しいツールが必要だ。1つはmemberという関数で、要素が配列の中に見つかったかどうかを判定する。ルートは名前の配列として保持され、そして新しい場所にたどり着いたときは、アルゴリズムはmemberを呼び出してその場所が既に存在するかを判定する。このようなものになる。:
function member(array, value) {
var found = false;
forEach(array, function(element) {
if (element === value)
found = true;
});
return found;
}
print(member([6, 7, "Bordeaux"], 7));
しかしながら、もし値が最初の位置に直接見つかったとしても、これは配列全体に渡って探すだろう。これは無駄だ。forループを使うときはbreak文を使うことでで飛び出すことができたが、しかし、forEachの構造の中ではこれは動かない、なぜならループの中の本体は関数であり、break文では関数から抜け出せないからである。1つの解決としてはbreakの信号を例外のあらかじめ決めておいた一種として扱うよう、forEach関数を変更することだ。
var Break = {toString: function() {return "Break";}};
function forEach(array, action) {
try {
for (var i = 0; i < array.length; i++)
action(array[i]);
}
catch (exception) {
if (exception != Break)
throw exception;
}
}
今、もしaction関数がBreakを投げたら、forEachが例外を吸収してループを止めるだろう。このオブジェクトは、純粋に比較のために使われる変数Breakを格納する。これにtoStringプロパティを与えた理由は、これにより、BreakをforEachの外に何らかの理由で投げ上げたとき、おかしな値を表示できた方が便利になるからだ。
forEachループから抜け出せる手段を持つことはとても便利だが、この場合のmember関数は結果としてまだ醜いものであり、なぜならそれは固有の結果を格納して後でそれを返す必要があるからだ。もう一つの種類の例外Returnを加えて、ふさわしいvalueを与えられたら、例外を投げて、この値をforEachが返すようにすることもできる。しかし、これは恐ろしくその場しのぎで乱雑だ。本当に必要なのは全く新しい高階関数で、any(もしくは、時々はsomeと)と呼ばれる。このようなものだ。:
function any(test, array) {
for (var i = 0; i < array.length; i++) {
var found = test(array[i]);
if (found)
return found;
}
return false;
}
function member(array, value) {
return any(partial(op["==="], value), array);
}
print(member(["Fear", "Loathing"], "Denial"));
anyは配列の要素に渡って、左から右へ、テスト関数を適用していく。テスト関数がこれは真になるような値を返した1回目は、anyはその値を返す。もし真になるような値が見つからなければ、falseが返される。any(test, array)を呼ぶことで、多かれ少なかれ、test(array[0]) || test(array[1]) || ... etcetera.と同じようななことが行われる。
&&が||の仲間であるように、anyはeveryと呼ばれる仲間を持つ:
function every(test, array) {
for (var i = 0; i < array.length; i++) {
var found = test(array[i]);
if (!found)
return found;
}
return true;
}
show(every(partial(op["!="], 0), [1, 2, -1]));
必要なもう一つの関数はflattenだ。この関数は配列の配列を受け取って、それらの配列の要素を1つの大きな配列にまとめる。
function flatten(arrays) {
var result = [];
forEach(arrays, function (array) {
forEach(array, function (element){result.push(element);});
});
return result;
}
同じことはconcatメソッドとreduceを使ってやることもできた、しかしこれは効率がが悪い。文字列の連結の繰り返しが、それらを配列に入れた上でjoinするより遅いのと似たように、配列の連結を繰り返し行うことは、不必要に多くの中間配列の値を作ることになる。
[演習 7.2]
ルートを作り始める前に、もう一つ高階関数が必要だ。これはfilterと呼ばれる。mapと似て、関数と配列を引数として取り、新しい配列を作るが、しかし呼ばれた関数の結果を新しい配列に入れる代わりに、古い配列に与えられた関数を適用した結果が真であるような値の場合にだけ、その値を新しい配列に入れる。この関数を書け。
[解答を見る]
function filter(test, array) {
var result = [];
forEach(array, function (element) {
if (test(element))
result.push(element);
});
return result;
}
show(filter(partial(op[">"], 5), [0, 4, 8, 12]));
(もしfilterを適用した結果に驚いたら、partialに与えられた引数の最初のものが関数であり、その残りが>に与えられることを思い出そう。)
ルートを生成するこのようなアルゴリズムを想像する―スタート地点から開始して、そこから移動する全ての道路についてのルートを生成する。これらの道路毎の終点についたら、その先のルートを生成し続ける。1つの道路に沿ってではなく、分岐する。このため、再帰がこれをモデル化する自然な手段である。
function possibleRoutes(from, to) {
function findRoutes(route) {
function notVisited(road) {
return !member(route.places, road.to);
}
function continueRoute(road) {
return findRoutes({places: route.places.concat([road.to]),
length: route.length + road.distance});
}
var end = route.places[route.places.length - 1];
if (end == to)
return [route];
else
return flatten(map(continueRoute, filter(notVisited,
roadsFrom(end))));
}
return findRoutes({places: [from], length: 0});
}
show(possibleRoutes("Point Teohotepapapa", "Point Kiukiu").length);
show(possibleRoutes("Hanapaoa", "Mt Ootua"));
関数は、それぞれがルートが通過する場所と、その長さの配列を含むrouteオブジェクトの配列を返す。findRouteは可能は全てのルートの展開の配列を返すことを再帰的に繰り返す。行こうとしていたルートの終点に到着したとき、それがただ通過してきたルートを返すだけでは意味がない。もしそこが別の場所であれば、行く必要がある。flatten/map/filterの行はおそらく最も読みにくい場所だろう。これは’今の場所から全ての道路を取るが、既に行ったことのある場所は除く。これらの道路毎に、終わったルートの配列を与え、これらのルートを大きな単一の配列にして返す。’と言っている。
その行は多くのことをやっている。これが抽象化の良いところだ。:これらにより複雑なことを画面一杯のコード無しでできるようになる。
これは永遠には再帰しない、自分自身がどのように呼ばれたか(continueRouteから?とか)記憶していているのだろうか?いや、いくつかの点で異なり、既に通った場所に出ていく全ての道路ではfilterの結果として空の配列が返る。空の配列をmapした結果は空の配列となり、flattenに空の配列を与えた場合にもそうなる。行き止まりでfindRouteを呼び出せば空の配列が作られ、それは’これ以上、このルートには続く道がない’という意味になる。
pushではなくconcatで場所がルートに追加されていることに注意。concatメソッドは新しい配列を作り、pushは既存の配列を変更する。なぜなら、この関数は単一の部分的なルートからいくつかのルートに枝分かれし、何回も使われるため、元のルートを表現する配列を変更してはならないのである、
[演習 7.3]
今我々が持っている全ての可能なルートから一番短いものを探そう。possibleRouteと同様に、開始地点と終了地点の名前を引数に取る、shortestRoute関数を書け。possibleRouteが作るものと同様の型で単一のrouteオブジェクトを返すこと。
[解答を見る]
function shortestRoute(from, to) {
var currentShortest = null;
forEach(possibleRoutes(from, to), function(route) {
if (!currentShortest || currentShortest.length > route.length)
currentShortest = route;
});
return currentShortest;
}
‘最小化’や’最大化’のアルゴリズムのトリッキーな点は空の配列が与えられたときに台無しになるところだ。この場合、全ての2地点間の道路を知っていたので、それをただ無視することができた。しかし、これは少々不十分である。もしPuamuaからMount Ootuaへの道が険しく、豪雨で洗われたために泥だらけになっていたら?もし、これで我々の関数をぶちこわしになるとしたら恥ずかしいので、道が見つからなかった場合はnullが返るようにしよう。
それから、とても関数的な、できる限りなんでも抽象化するアプローチ:
function minimise(func, array) {
var minScore = null;
var found = null;
forEach(array, function(element) {
var score = func(element);
if (minScore == null || score < minScore) {
minScore = score;
found = element;
}
});
return found;
}
function getProperty(propName) {
return function(object) {
return object[propName];
};
}
function shortestRoute(from, to) {
return minimise(getProperty("length"), possibleRoutes(from, to));
}
残念なことに、これは実行時間が他のバージョンより3倍ほど長い。プログラムの中で、いくつかのものの最小を求める必要があれば、このような一般的なアルゴリズムを書いて、それを再利用するのがいいアイデアだ。多くの場合においては最初のバージョンでおそらく十分だ。
getProperty関数に注意。これはオブジェクトの関数的プログラミングにおいてしばしば便利だ。
Point kikiuからPoint Teohotepapapaまでのルートをこのアルゴリズムで見てみよう…
show(shortestRoute("Point Kiukiu", "Point Teohotepapapa").places);
ヒバオアのような小さな島では、全ての可能なルートを生成するのは大きすぎる仕事ではない。言わばベルギーみたいな、もっと合理的なレベルで詳細な地図に対してこのようなことをやるのであれば、馬鹿げたほどの長い時間と、大量のメモリが必要になるだろう。それでも、そのようなオンライン・ルート・プランナーを見た事があるだろう。これらは巨大な迷路から多少なりとも望ましいルートを2, 3秒で教えてくれる。どうやってやっているのだろうか?
もし注意していれば、終点に至る全ての道を生成する必要は必ずしもないということに気づいたかもしれない。もしルートの構築時に比較を始めていれば、ルートの巨大なセットを構築することを回避でき、そして目的地への単一のルートをすぐに見つけることができ、既に見つけたものより長いルートの展開をやめることができただろう。
これを見てほしい。地図に20×20のマスがある。:

今見ているのは山の地形の高度図である。黄色い点が頂上、青い点が谷。この領域が100m大の四角に分割されている。我々には、xとyプロパティで示された地図の任意の地点の高さをメートルで返してくれるheightAt関数を与えられている。
print(heightAt({x: 0, y: 0}));
print(heightAt({x: 11, y: 18}));
この地形を徒歩で横切って、左上から右下に行きたい。マスはグラフのように扱える。全ての四角はノードであり、周囲の四角に接続されている。
エネルギーを浪費したくないので、なるべく簡単な道を行きたい。登り坂を行くのは下り坂を行くより辛い。下り坂を行くのは平坦な道を行くより辛い。この関数は、隣り合った2つの四角の間を歩く(または登る)ことでどれだけ疲れるかを表現した、’重み付けされたメートル’を計算する。上り坂を行くのは下り坂を行くより2倍の重さがあると数える。
function weightedDistance(pointA, pointB) {
var heightDifference = heightAt(pointB) - heightAt(pointA);
var climbFactor = (heightDifference < 0 ? 1 : 2);
var flatDistance = (pointA.x == pointB.x || pointA.y == pointB.y ? 100 : 141);
return flatDistance + climbFactor * Math.abs(heightDifference);
}
flatDistanceの計算に注意。もし2つの地点が同じ行か列にあれば、それらは実際に互いの隣にあって、その間の距離は100mである。そうでなければ、それらが対角線上で接していると仮定し、その2地点間の対角線の距離は2の平方根に100をかけた長さ、およそ141である。この関数を1ステップより遠く離れた四角同士の計算に使ってはならない。(ダブルチェックが必要になり…面倒すぎる。)
地図上の地点はxとyプロパティを持つオブジェクトによる表現される。そのオブジェクトを使うときに、これら3つの関数があれば便利だろう。:
function point(x, y) {
return {x: x, y: y};
}
function addPoints(a, b) {
return point(a.x + b.x, a.y + b.y);
}
function samePoint(a, b) {
return a.x == b.x && a.y == b.y;
}
show(samePoint(addPoints(point(10, 10), point(4, -2)),
point(14, 8)));
[演習 7.4]
もしこの地図を横切るルートを見つけるとき、与えられた地点から取れる方向のリストという’標識’を作る関数が再度必要になる。pointオブジェクトを引数として取り、近くの地点の配列を返すpossibleDirection関数を書け。我々は、まっすぐ、あるいは対角線上の隣接した地点しか移動できず、四角は最大8つの隣の四角を持つものとする。地図の外の四角を返すことのないように注意。地図の端は世界の端とみなす。
[解答を見る]
function possibleDirections(from) {
var mapSize = 20;
function insideMap(point) {
return point.x >= 0 && point.x < mapSize &&
point.y >= 0 && point.y < mapSize;
}
var directions = [point(-1, 0), point(1, 0), point(0, -1),
point(0, 1), point(-1, -1), point(-1, 1),
point(1, 1), point(1, -1)];
return filter(insideMap, map(partial(addPoints, from),
directions));
}
show(possibleDirections(point(0, 0)));
mapSize変数を作り、その唯一の目的は同じことを20回書く必要をなくすことである。もし、他の時に、別の地図について同じ関数を使うことになったら、コードのあちこちが20で満たされ、それら全てを変更しなければならないというのは馬鹿馬鹿しい。別の地図に対してもこの関数を変更しなくても良いように、mapSizeをpossibleDirectionの引数として与えるだろう。この場合は、実際にそういうことが起こってから変えればいい、今回は必要ないと判断した。
それから、なぜ0を持つ変数も作らなかったかといえば、それが2回も発生するか?ということにある。私は地図は0からスタートすると仮定していて、これが今後残念ながら変更になることがあるとしても、そのために1つの変数を使うのはただノイズを増やすことでしかない。
ブラウザにそれを渡すことなしに、この地図からルートを見つけるのはプログラムから省略する、なぜならそこまで終わらせるのは長くかかりすぎるからである。我々は素人っぽい試みをやめて真剣なアルゴリズムを実装しよう。過去において、このような問題に多くの作業がつぎ込まれ、多くの解決策(あるものは輝かしく、他は無益だった)が設計された。とても人気があり効果的なのはA*(A-starと発音する)である。この章の残りを、この地図のA*ルート探索関数の実装に費やそう。
アルゴリズムそれ自身を得る前に、解決すべき問題についてもう少し話そう。グラフを使ってルートを探索することに伴うトラブルは、大きなグラフは、とても恐ろしいほどの数のグラフになるということにある。ヒバオアの道路探索では、グラフは小さく、我々に必要だったのは、既に通過した地点を再度訪れることを確実に避けることにあった。新しい地図では、これではもう十分であるとは言えない。
根本的な問題は、間違った方向に行く可能性が多すぎるということだ。ゴールに向かっての道の探検の舵取りは何らかの管理なしには、正しい道より間違った道を進み続けることを我々に選択させることになるだろう。もし、そのような道を生成し続け、莫大な道をたどって、その中の1つが偶然に終点についたとしても、それが最短の道かどうかは分らない。
ここで欲しいものは、探検する方向が、まず、あなたを終点に近づけているかだ。この地図のようなマス目では、どのくらいの長さかとその終点が目的地にどれだけ近いかによって、どのくらい良い道かを荒く見積もることができる。道の長さとまだ残っている長さの見積もりを加算することによって、それらの道が有望かどうかのおおまかなアイデアを得られる。もし有望な道を最初に拡張すれば、使えない道で無駄にする時間は少なくなるだろう。
しかしそれでもまだ十分ではない。もし地図が完全に平坦な平面なら、有望そうに見える道はほとんど常に一番いい道で、その道の通りにゴールへ歩いて行けば良い。しかし、谷や尾根が我々の道を阻んでおり、それで最も効率的な道の方向に進むのが難しくなっている。このために、まだ多くの道を探検しなければならない。
これを正すには、最も有望な道を常に探検するということをうまくやることだ。一度X地点までの一番いい道がAであると分ったら、そのことを記憶しておける。その後で、道BもまたX地点に行くと分ったときは、それは一番いい道ではないと分るし、それ以上探検する必要はなくなる。
であるから、そのアルゴリズムはこのようになるだろう…
データの2つの部品を持っておく。1つめはオープン・リストと呼ばれ、まだ探検しなければならない部分的なルートが入っている。ルート毎に得点を持ち、それはその長さとゴールからの距離を加算して計算する。この距離は常に楽観的なもので、距離を過大評価しないようにする。2つめは既に見たノードのセットで、すでに見つけた最短の部分的なルートが一緒に入っている。これをリーチド・リストと呼ぼう。我々は開始地点のノードだけが入っているルートをオープン・リストに加えるところから始めて、それをリーチド・リストに記録するのだ。
それから、オープン・リストにノードがある間、その一つについて最も低い(良い)点数のものを取り、続けられる限り(possibleDirectionをコールして)道を探す。これが返すノード毎に、元のルートにこれらを加えた新しいルートを作り、そしてルートの長さをweightDistanceを使って修正する。これらの新しいルートそれぞれの終点をリーチド・リストの中から探す。
もしそのノードがリーチド・リストの中にまだなければ、それは前に到達していないという意味になるから、新しいルートをオープン・リストに加えて、リーチド・リストに記録する。もし、前に到達していたら、新しいルートの得点とリーチド・リストの中のルートの得点を比較し、もし新しいルートが短ければ、既にあるルートを新しいルートに置き換える。そうでなければ、今の地点に至るより良い道が既にあるということなので、新しいルートは破棄する。
我々はこれをオープン・リストから取り出したルートがゴールのノードに到達するまで繰り返し、その場合我々はルートを見つけたことになる。またはオープン・リストが空になるまで繰り返し、その場合はルートが見つからなかったということになる。我々の地図には越えられない障害は含まれていないから、常にルートはある。
どうすれば、オープン・リストから得た最初の全ルートをが最短のものでもあると知ることができるだろうか?これは、このルートが最低の得点を持っているという事実の結果でしかない。ルートの得点は実際の長さプラス残りの長さの楽観的な見積もりだ。これは、もしルートがオープン・リストの中で、もっとも低い得点を持つなら、それが常に現在の終点への一番良いルートである – この地点にたどり着くもっと良い道を、後から他のルートに見つけることは不可能であり、なぜなら、もしそれがもっと良い道であるなら、その得点の方が低くなっているはずだからである。
この作業がまだとらえどころがないということで、イライラしないように。このようなアルゴリズムについて考えるときは、’そのようなもの’として見ることが、アプローチの比較をする上で見るべきポイントをあなたに与え、大いに助けになる。初心者プログラマーはこのようなポイントを見ることなしに作るから、簡単に見失うのである。ただこれが進んだやりかたであるとだけ理解し、章の残り全体を読んで、後で挑戦してみたくなったら、戻ってくるといい。
心配なのは、アルゴリズムの1つの面で、魔法を発動しなければならなそうなことだ。オープン・リストは多くのルートを持つことができなければならないし、その中から最低の得点のルートを素早く見つけなければならない。通常の配列に格納して、毎回この配列を検索するのでは遅すぎる。バイナリー・ヒープというデータ構造を教えよう。それは、Dateオブジェクトと同じようにnewによって作られ、引数で与えられた要素を’採点’する関数を与えられる必要がある。結果のオブジェクトは配列のようにpushとpopメソッドを持つが、しかしpopは、最後にpushされた要素の代わりに、常に最低のスコアをもつ要素を取り出すのだ。
function identity(x) {
return x;
}
var heap = new BinaryHeap(identity);
forEach([2, 4, 5, 1, 6, 3], function(number) {
heap.push(number);
});
while (heap.size() > 0)
show(heap.pop());
Appendix 2でこのデータ構造の実に興味深い実装について論じている。8章を読み終わった後に、それを見たくなるかもしれない。
できる限りの効率を絞り出す必要があるので、これと別の効果的な手段も用いる。ヒバオアのアルゴリズムはルートを格納するために場所の配列を持っていて、これらは拡張するときにconcatメソッドでコピーされた。今回、探検すべきルートが多すぎるため、我々には配列をコピーする余裕はない。代わりに、ルートを格納するためにオブジェクトの鎖を使う。鎖の中の全てのオブジェクトは地図上のポイント、ルートの長さのようなプロパティを持ち、また鎖の中の直前のポイントのプロパティも持つ。このようなものだ。:
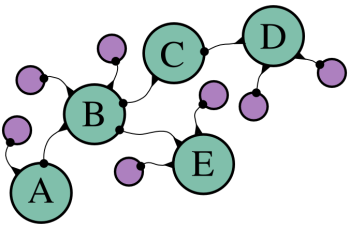
シアンの円の場所は関係のあるオブジェクト、そして線はプロパティを表現している – 点になっている終端はプロパティの値を指す。オブジェクトAはルートの開始地点である。オブジェクトBは、Aからの続きである新しいルートを作る。それは呼び出すと、そのルートの開始地点を示す、fromプロパティを持つ。後でルートを再構築することが必要になったとき、これらのプロパティで既に通ったルートの全ての地点をたどることができる。オブジェクトBが2つのルートの部分になっていることに注意。1つはD、もう1つはEで終わっている。多くのルートがあったときにこれが記憶装置の容量を節約してくれる – 全ての新しいルートはそれ自身の1つのオブジェクトしか必要とせず、残りはスタート地点から同じ経路を通っている他のルートと共有している。
[演習 7.5]
2つの地点間の距離の楽観的な見積もりを出すestimateDistance関数を書け。高度のデータを見る必要はないが、しかし平坦な地図であると仮定できること。まっすぐ、あるいは対角線上にしか進むことができないこと、そして対角線上の2つの四角の距離は141として数えることを念頭に置く。
[解答を見る]
function estimatedDistance(pointA, pointB) {
var dx = Math.abs(pointA.x - pointB.x),
dy = Math.abs(pointA.y - pointB.y);
if (dx > dy)
return (dx - dy) * 100 + dy * 141;
else
return (dy - dx) * 100 + dx * 141;
}
変な数式は道をまっすぐな部分と斜めに進む部分に分解するためのものだ。もし、このような道があるとして…
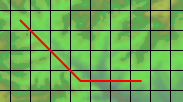
…道は横方向に四角8つ分、縦方向に4つ分あり、8 - 4 = 4だけまっすぐ、4だけ斜めに進む。
もし、ただポイント間のまっすぐなピタゴラスの距離を計算する関数を書いたら、それもまた動くだろう。我々が必要としているのは楽観的な見積もりで、まっすぐゴールに向かうことができると考えるのも確かに楽観的だ。しかしながら、より本当の距離に近い見積もりは、プログラムが意味のない道を試すことを減らすだろう。
[演習 7.6]
オープン・リストにバイナリ・ヒープを使う。リーチド・リストに良いデータ構造は何だろうか。これは与えられたx、y座標のペアからルートを探すのに使う。なるべく早い方法で。makeReachedList、storeReached、findReacedListの3つの関数を書け。1つめはデータ構造をつくるもの、2つめは与えられたリーチド・リストに地点とルートを格納するもの、3つめは与えられたリーチド・リストと地点からルートを取り出すか、もしその地点へのルートが見つからない場合にはそのことを示すためにundefinedを返す。
[解答を見る]
1つの合理的なアイデアは、中にオブジェクトを格納するオブジェクトを使うことだ。1つの地点の座標、言わばxは外側のオブジェクトのプロパティの名前として使われ、他方、yは内側のオブジェクトである。これは、ときどき、探している内側のオブジェクトが(まだ)そこにないという事実を扱うために記録を必要とする。
function makeReachedList() {
return {};
}
function storeReached(list, point, route) {
var inner = list[point.x];
if (inner == undefined) {
inner = {};
list[point.x] = inner;
}
inner[point.y] = route;
}
function findReached(list, point) {
var inner = list[point.x];
if (inner == undefined)
return undefined;
else
return inner[point.y];
}
他の可能性は地点のxとyを1つのプロパティ名に合併し、それをルートを格納する単一のオブジェクトの名前に使うことだ。
function pointID(point) {
return point.x + "-" + point.y;
}
function makeReachedList() {
return {};
}
function storeReached(list, point, route) {
list[pointID(point)] = route;
}
function findReached(list, point) {
return list[pointID(point)];
}
データ構造を作り、操作する関数のセットを提供することによって、データ構造の型を定義するのは便利なテクニックだ。それはデータ構造それ自体の詳細からデータ構造を使うコードの’分離’を可能にする。上記2つの実装のどちらを使っても、リーチド・リストを必要とするコードは全く同じように動くことに注意。使われているオブジェクトの種類に気を遣うことなく、期待する結果を手に入れることができる。
このことについて8章でもっと詳しく論じ、そこでBinaryHeapのように、newによって作られ、メソッドを持つオブジェクト型の作り方を学ぶ。
実際の経路探索関数は最終的にはこうなる。:
function findRoute(from, to) {
var open = new BinaryHeap(routeScore);
var reached = makeReachedList();
function routeScore(route) {
if (route.score == undefined)
route.score = estimatedDistance(route.point, to) +
route.length;
return route.score;
}
function addOpenRoute(route) {
open.push(route);
storeReached(reached, route.point, route);
}
addOpenRoute({point: from, length: 0});
while (open.size() > 0) {
var route = open.pop();
if (samePoint(route.point, to))
return route;
forEach(possibleDirections(route.point), function(direction) {
var known = findReached(reached, direction);
var newLength = route.length +
weightedDistance(route.point, direction);
if (!known || known.length > newLength){
if (known)
open.remove(known);
addOpenRoute({point: direction,
from: route,
length: newLength});
}
});
}
return null;
}
まず、必要なデータ構造、1つはオープン・リスト、1つはリーチド・リストを作る。routeScoreは与えられたバイナリー・ヒープの得点をつける関数だ。何度も再計算するのを防ぐためにrouteオブジェクトにその結果を格納していることに注意しよう。
addOpenRouteは新しいルートをオープン・リストとリーチド・リストの両方に追加する便利な関数だ。ルートの開始地点を明示的に加えるのに遣われる。routeオブジェクトは常に、ルートの終わりを持つpoint、ルートの現在の長さを持つlengthプロパティを持つ。四角1つ分以上の長さを持つルートは、その直前の地点を示すfromプロパティも持つ。
アルゴリズムの中に記述されたwhileループは、オープン・リストから最低の点数のルートを取り続け、そしてゴール地点にたどり着いたかチェックする。もしそうでなければ、その展開を続ける。それはforEachで行われる。この新しい地点をリーチド・リストから探す。もしそこになければ、あるいは見つけたノードの持つルートの長さが新しいルートの長さより長ければ、新しいrouteオブジェクトが作られオープン・リストとリーチド・リストに加えられ、(もしあれば)既存のルートがオープン・リストから取り除かれる。
もしknownの中のルートがオープン・リストにない、とはどういうことか?ルートがオープン・リストから取り除かれるのは、その終点への最も楽観的なルートが見つかった時でなければならない。もしそうでないのにバイナリー・ヒープから値を取り除こうとしたら例外が投げられるので、私の理論が間違っていれば、おそらく関数の実行中に例外を見ることになるだろう。
コードが確かにそうなっているか疑わしくなるほど複雑になったとき、何か間違っているときに例外を起こすチェックを加えるのはいいアイデアだ。そうすれば、何か奇怪なことが’静かに’起こっているかどうか知ることができ、何かを壊したとき、何を壊したか明示的に見ることができる。
このアルゴリズムが再帰を使っていないことに注意、しかしそれでも全ての分岐を探検することができる。オープン・リストが、ヒバオア問題の再帰の解決の中で関数呼び出しのスタックが果たしているのと同じような役割を担って – 探検しなければならない道を記録し続けている。全ての再帰アルゴリズムは、’まだやらなければないこと’を格納するデータ構造を使うことにより、再帰しない方法で書くことが可能だ。
よし、この経路探索を試してみよう:
var route = findRoute(point(0, 0), point(19, 19));
もし上記のコード全てを実行して、何のエラーもでなかったら、実行するのに2, 3秒ほどかかり、1つのrouteオブジェクトを返すだろう。このオブジェクトはまだ読みにくい。もしコンソールが十分大きいなら、地図上で1つのルートを見せてくれる、showRoute関数がその助けになるだろう。
showRoute(route);
その方が便利なら、複数のルートをshowRouteに渡すこともできる。例えば、11,17の美しい景観を含む景色のいいルートを試そう。
showRoute(findRoute(point(0, 0), point(11, 17)),
findRoute(point(11, 17), point(19, 19)));
グラフ通じての楽観的なルート探索のテーマのバリエーションは多くの問題に適用することができ、その多くは物理的な経路に関連したものだけに留まらない。例えば、複数のブロックを限られたスペースに詰め込むパズルを解くプログラムが必要になったときは、決まった場所に決まったブロックを入れようとすることを’経路’のバリエーションとして探索することができる。最後のブロックを入れる場所がなければ経路は行き止まり、全てのブロックがはまった経路がパズルの解答になる。